Who won the election -- Quadratic to Linear Time!!!!!
Last week was crazy. Busy, stressful, late night after late night. It ended, though, on a great note.
A young lady in my intro class found me in my office near the end of the day:
Student: Mr. Z, I wanted to make sure to catch you before vacation!
Me: What's up?
Student: I wanted to tell you that today's lesson was AWESOME!!!!!!
Wow. I've been teaching 23 years and that's never happened before!!!!
So, what was the hubbub about?
We've been doing list processing in Python over the past few days. We already did the basics, such as finding the largest element in a list:
{% highlight python linenos %}
def find_max(L):
maxval = L[0]
i=0
while i
We've also done basic searching, counting elements, removing elements, etc.
Today we started with finding the mode of a list of grades.
Most students approached the problem as a maximum problem. Assume the first item is the mode and find it's frequency, then proceed through the list each time seeing if the current node occurs more fequently than the "mode so far." Pretty much the same idea as find_max (but in this case, returning a list of all the modes).
{% highlight python linenos %} def mode(L): modecount = L.count( L[0] ) modes = [ L[0] ] i = 1 while i < len(L): c = L.count(L[i]) if c > modecount: modecount = c modes = [ L[i] ] elif c==modecount and L[i] not in modes: modes.append( L[i] ) i += 1 return modes
Pretty cool. The kids are doing something pretty sophisticated here.
Time to look deeper. We started running this on larger and larger data sets. Things started really slowing down at about 20K. We then timed things to get some numbers (thanks StackOverflow).
What was going on. The students pretty quickly honed in on the line that called L.count(L[i]) -- Hidden Complexity.
We haven't done big-O notation but the class easily saw that count had to go through the entire data set and we ended up with an N^2 algorithm. For example, if we have 10 items, the main loop executes 10 times and each time, count goes through the entire list (10 items) as well. If we go to 100 items, it becomes 100x100.
What to do????
Time to talk about what's probably the most discussed instance of mode finding - elections. The winner is "the mode of the ballots."
Of course we don't use the above algorithm. We usually tally or count the ballots. We go through the ballots once, each time adding one to the appropriate candidates "bucket."
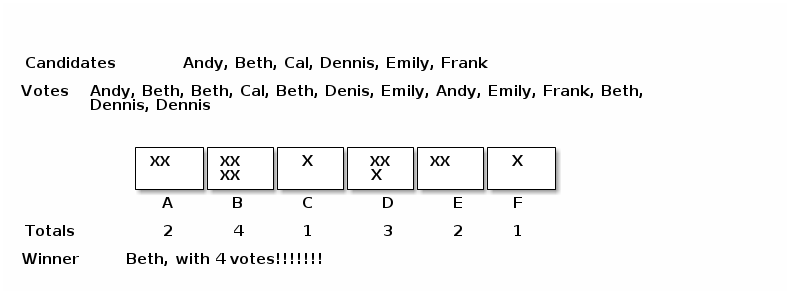
From here, it's a short step to see that we can use a list. It's indices represent the grade values and the data in the list the counts or tallies:
{% highlight python linenos %} def fastmode(L): i=0 counts = [] while i<max(L)+1: counts.append(0) i+=1 i=0 while i < len(L): counts[ L[i] ] += 1 i += 1 modecount = max(counts) modes = [] i=0 while i < len(counts): if counts[i]==modecount: modes.append(i) i=i+1 return modes
We go through the list once to build the tallies and then the "tally" list once to get the modes. Simple, straightforward, and linear time!!!!!!!!!
The original routine started to hit a roadblock at about 20K items, here we got to one million without breaking a sweat.
The take away:
- Get it working first.
- Then profile to find your bottleneck
- Look at the problem in a different way
- Using data structures in a clever way can really improve performance.
Comments
Comments powered by Disqus