A* is born
Over on the CS Educator StachExchange, which is in private beta for a few more days, I saw a post asking about how to introduce the A* search algorithm.
I taught A* as part of the APCS class at Stuy so I thought I'd talk about what I did here.
Some time around mid year, we get to intermediate recursion. This is about the time, give or take, when we talk about the nlogn sorts.
We also build a recursive maze solver. It's a nice algorithm and a nice little program. It's around 15 lines of code to perform a recursive depth first search:
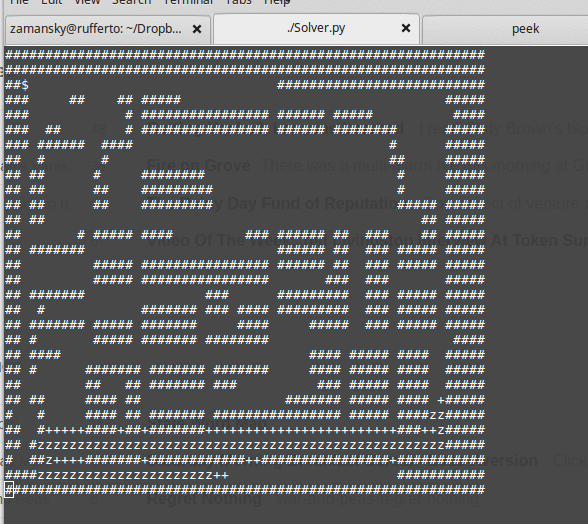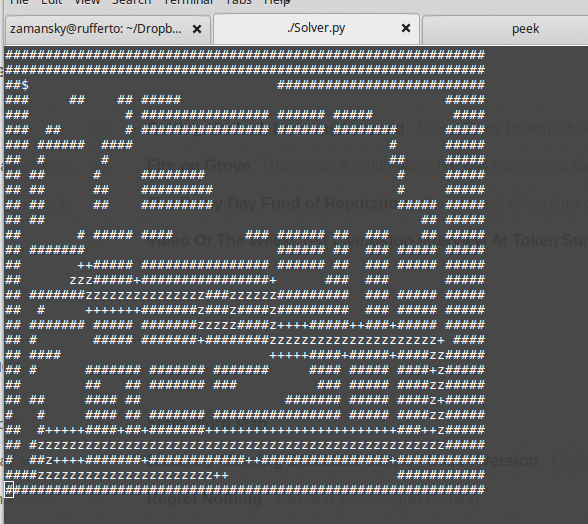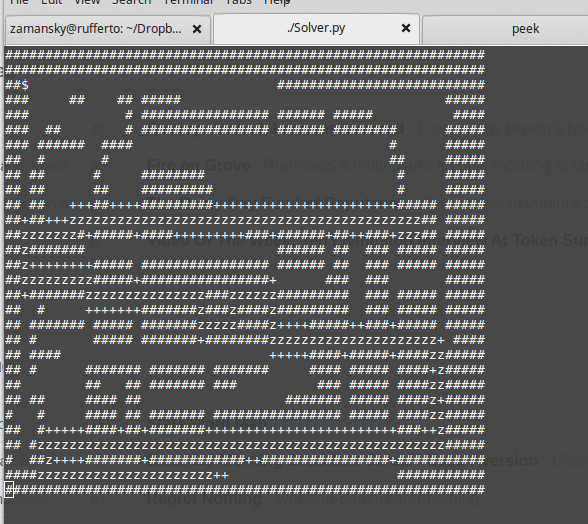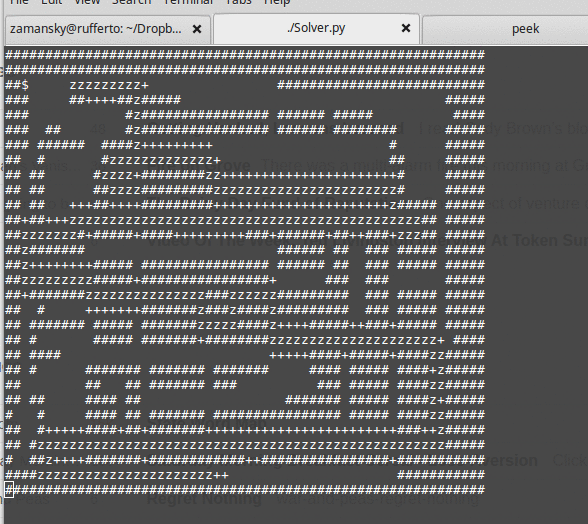
The basic algorithm is:
/* solve the maze from an x,ylocation */
solve(x,y){
if (we're at the exit)
Yay! We found the exit
if (we're at a wall or a visited space)
return (to previous step)
else {
mark current space as visited
solve(x+1,y)
solve(x-1,y)
solve(x,y+1)
solve(x,y-1)
}
}
It's a nice lesson because in addition to all the recursion stuff, we also get to talk about state space, state space search, backtracking, efficiency concerns and much more. After we finish the maze solver, we also talk about other problems that can be similarly examined using state-space search like the knights tour and N-queens problems.
A month or so later, when we're learning about stacks and queues as data structures, we revisit the maze solver. This time we solve the problem in a more general way. We talk about using a data structure to hold the set of nodes that we're aware of and that we want to visit next.
add start node to data structure
while data structure not empty{
current = remove item from data structure
if current is goal, return (we're done)
for every node adjacent to current that isn't yet visited{
mark that node as visited
add node to data structure
}
}
As we write the solution, we see that using a queue for this data structure yields a breadth first search:
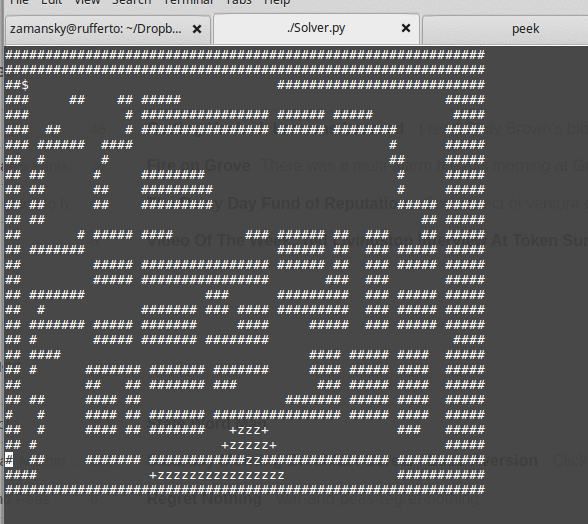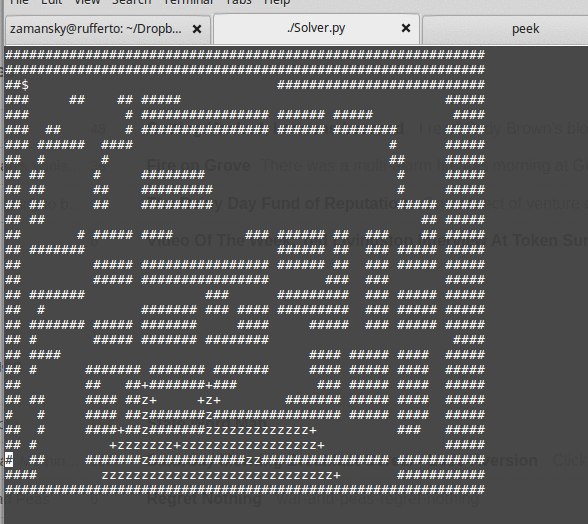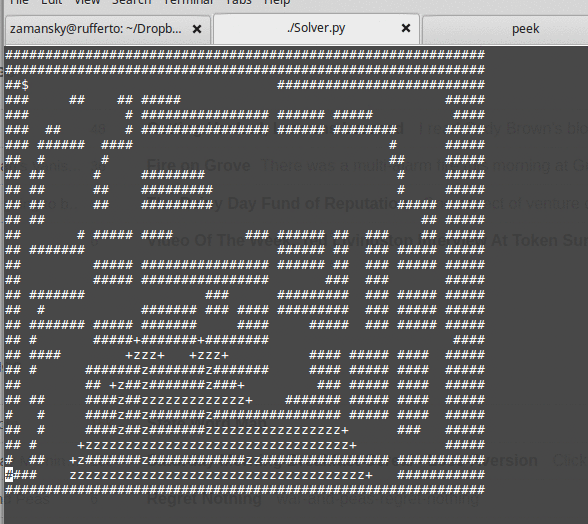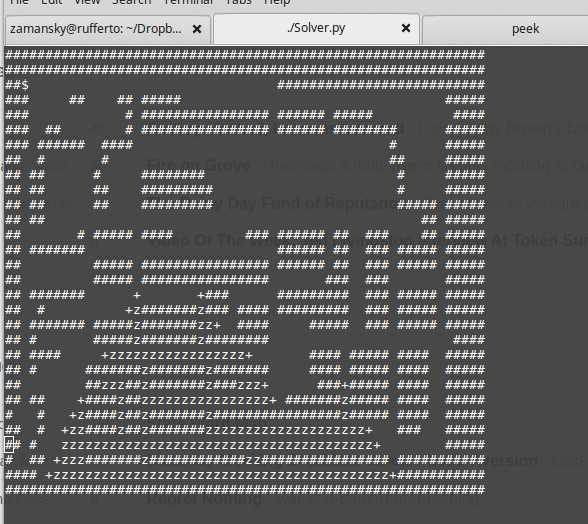
while using a stack yields depth first.
All of this leads to a discussion as to how deciding on which locations to look at next can greatly influence the steps to the exit. From here it's easy to see that you can use a heuristic to order the nodes in our data structure so that we explore "better" possibilities first. The data structure becomes a priority queue and we finally get to both "best first" and A* search:
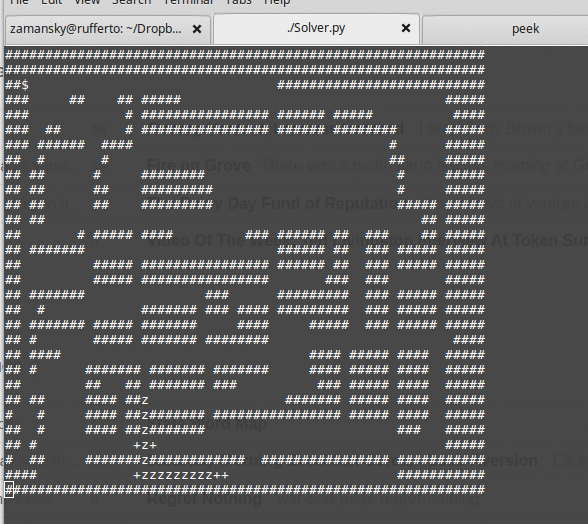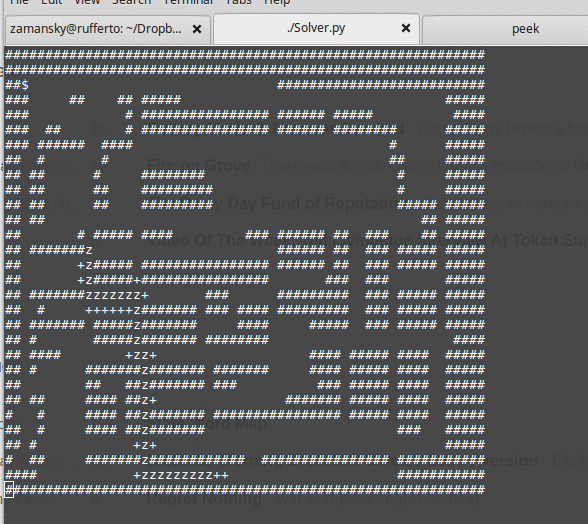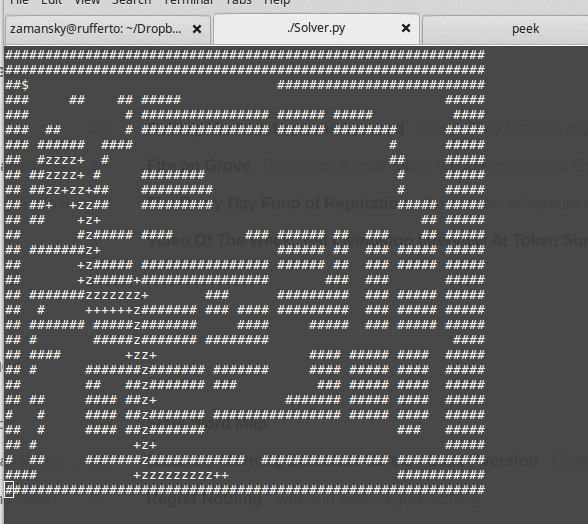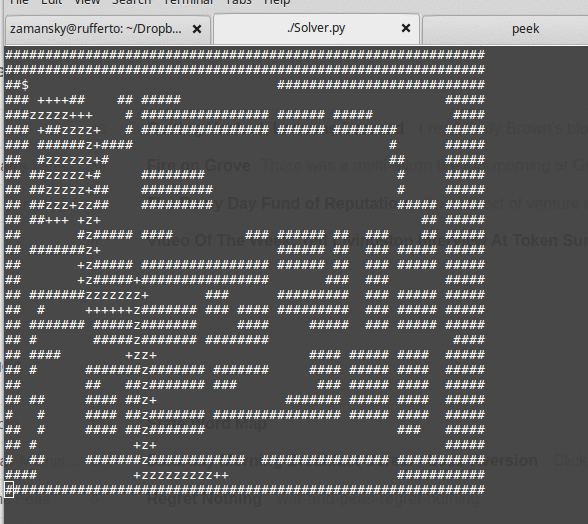
It's a nice sequence of lessons, albeit lessons spread out over months. The end result is that the students see both the need and motivation for something like A* and they see that it's not hard to implement. One basic routine where you can plug in one of three data structures - stack, queue, or priority queue to get very different results.
Comments
Comments powered by Disqus